ViT-B/16 discussion
Strong few-shot gains, but head behavior differs
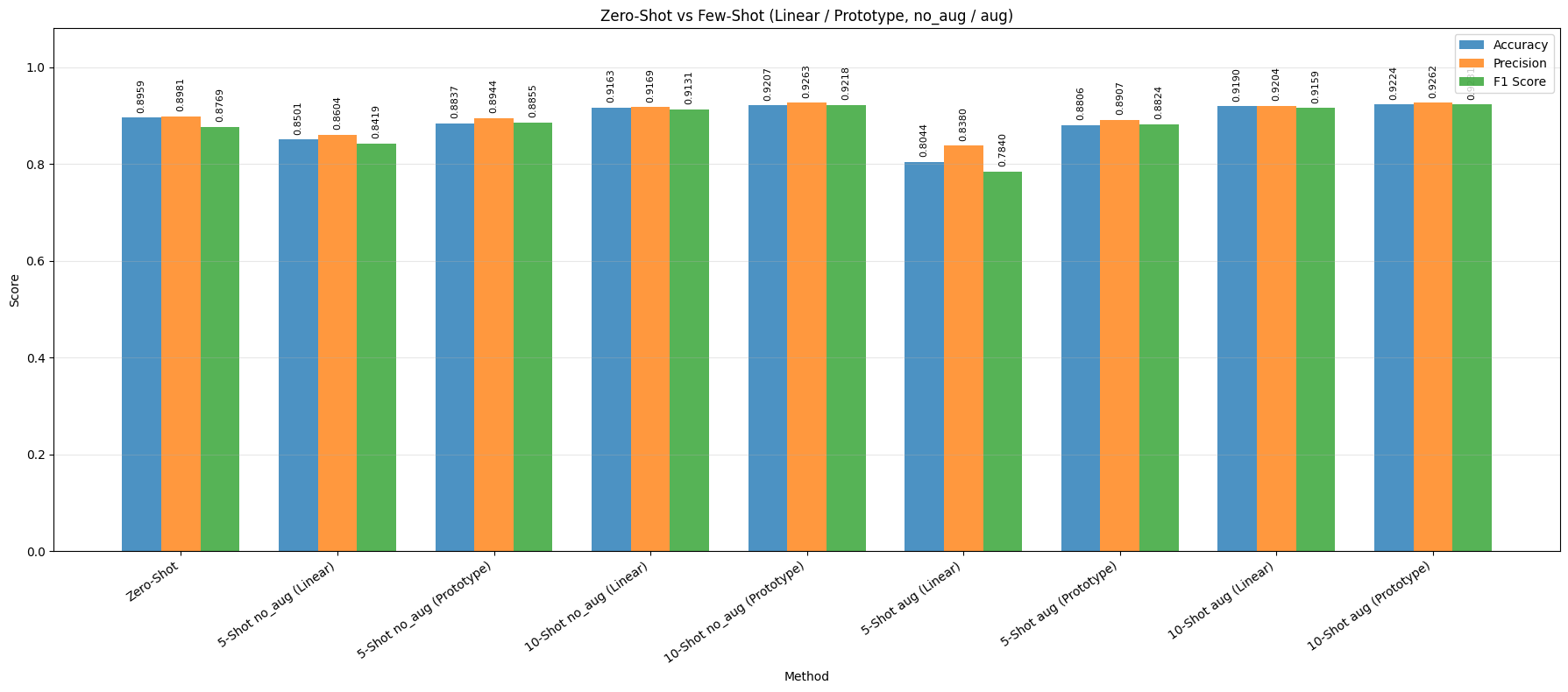
- Zero-shot ViT-B/16 is already a strong baseline with Accuracy = 0.8959 and F1 = 0.8769, showing that pretrained CLIP alignment transfers well to the multimodal food classification task.
- Moving from 5-shot to 10-shot clearly improves performance for both heads, confirming that a small increase in labeled support data is enough to improve class separation.
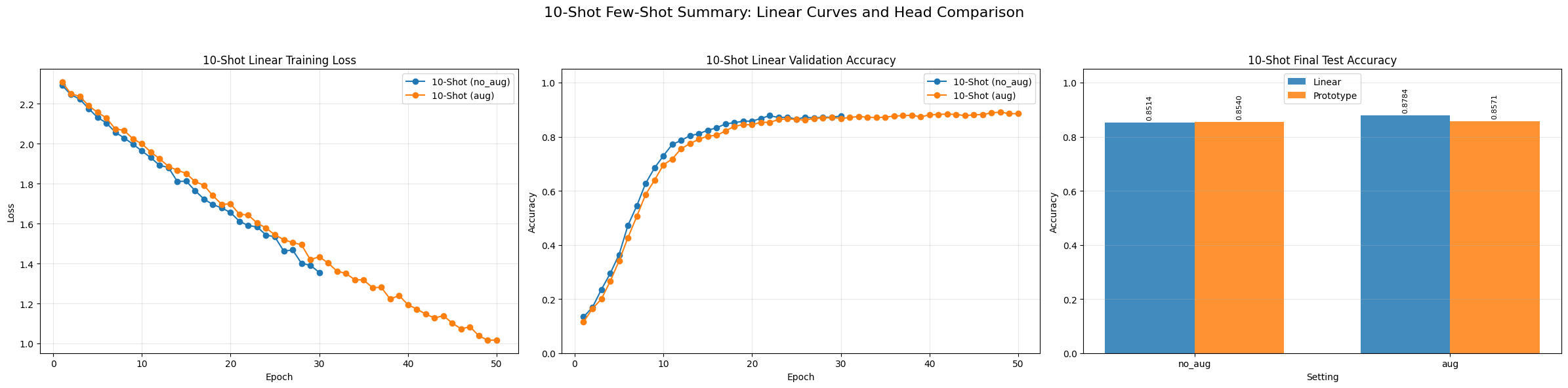
- The Prototype head is consistently more stable than the Linear head, especially in low-shot settings. The best overall ViT-B/16 result is Prototype + 10-shot + aug with Accuracy = 0.9224, Precision = 0.9262, and F1 = 0.9231.
- For the Linear head, augmentation is not helpful at 5-shot, but becomes beneficial at 10-shot. This suggests that stronger variation is useful only when the support set is large enough to stabilize the classifier.
RN50 discussion
More sensitive to setting and less consistent than ViT-B/16
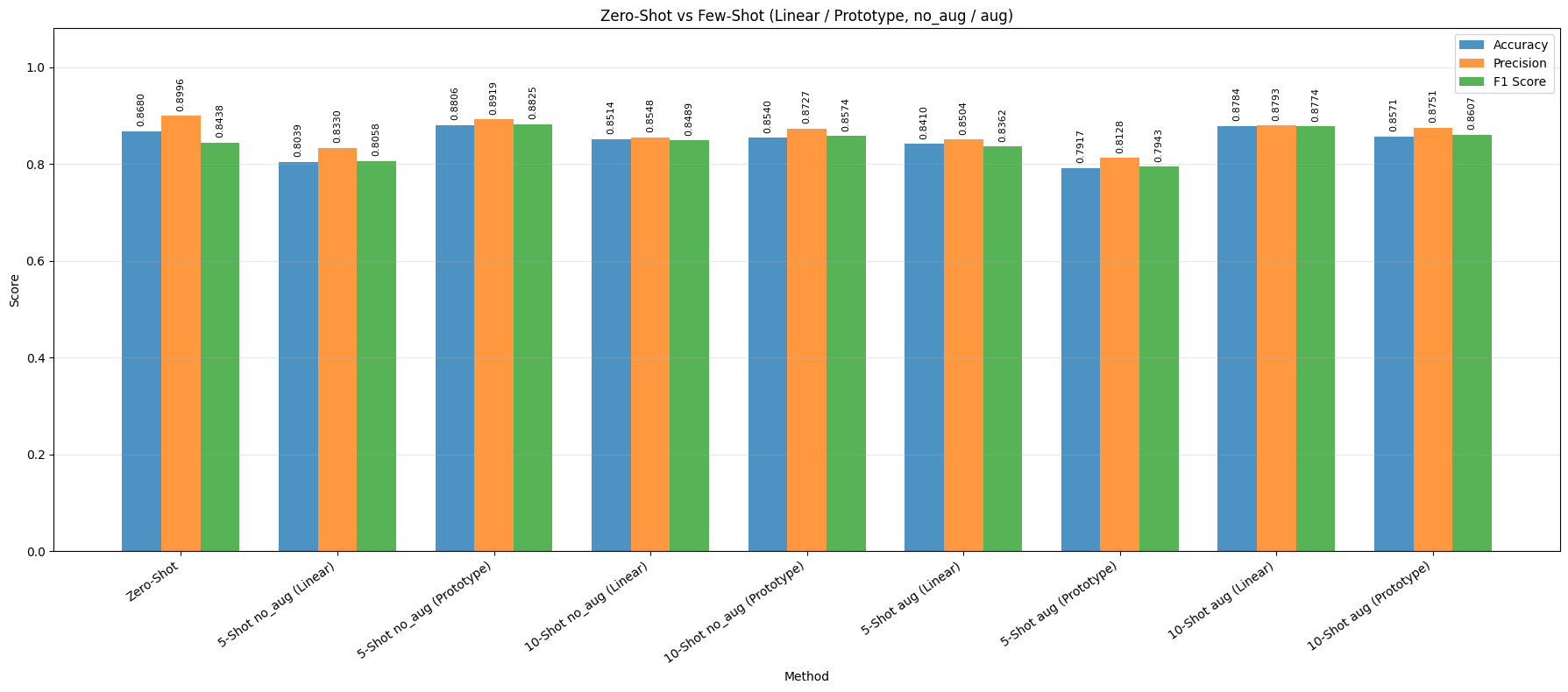
- RN50 zero-shot is also competitive with Accuracy = 0.8680 and F1 = 0.8438, but it remains below the ViT-B/16 baseline.
- Unlike ViT-B/16, RN50 does not improve consistently from 5-shot to 10-shot. Its behavior depends strongly on the classifier head and whether augmentation is applied.
- The best RN50 setting is Prototype + 5-shot + no_aug with Accuracy = 0.8806 and F1 = 0.8825, slightly outperforming RN50 zero-shot.
- For RN50, augmentation helps the Linear head in both shot settings, but it hurts the Prototype head at 5-shot. This indicates that RN50 is more sensitive to support-set quality and transformation noise than ViT-B/16.
Learning dynamics
Training curves and head comparison
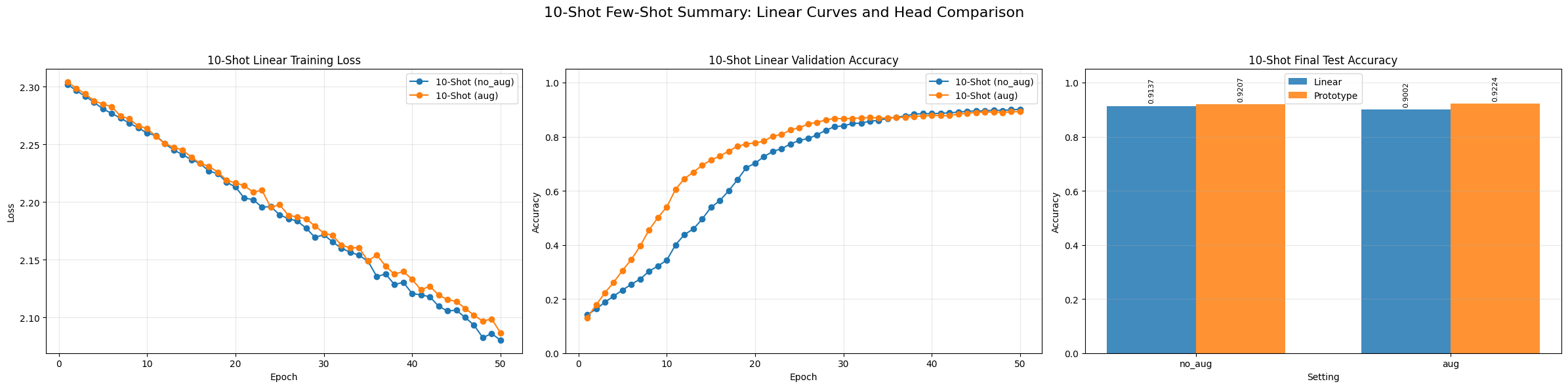
For ViT-B/16, the training-loss curves decrease smoothly and validation accuracy quickly saturates, indicating stable convergence for the 10-shot linear setting. The final comparison also shows that the Prototype head slightly outperforms the Linear head in both no_aug and aug settings.
For RN50, optimization is also stable, but the final ranking is less consistent across settings. This supports the observation that RN50 is more sensitive to the adaptation strategy and augmentation pipeline than ViT-B/16.
Calibration analysis
Prototype is reliable; Linear is under-confident
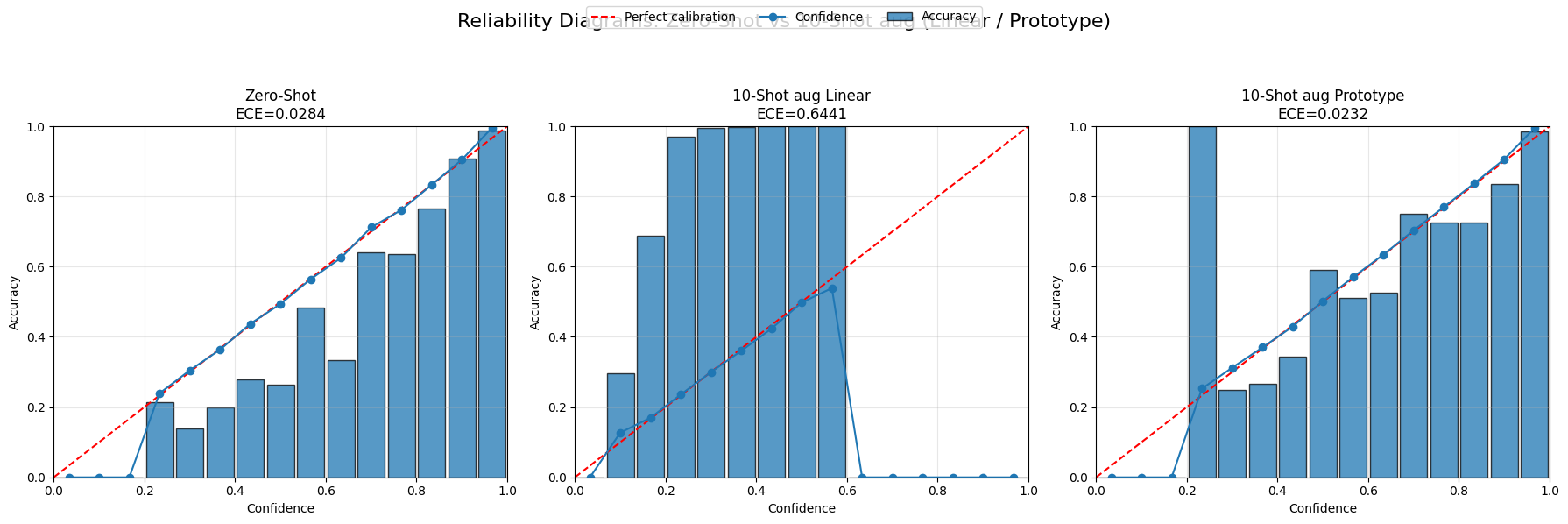
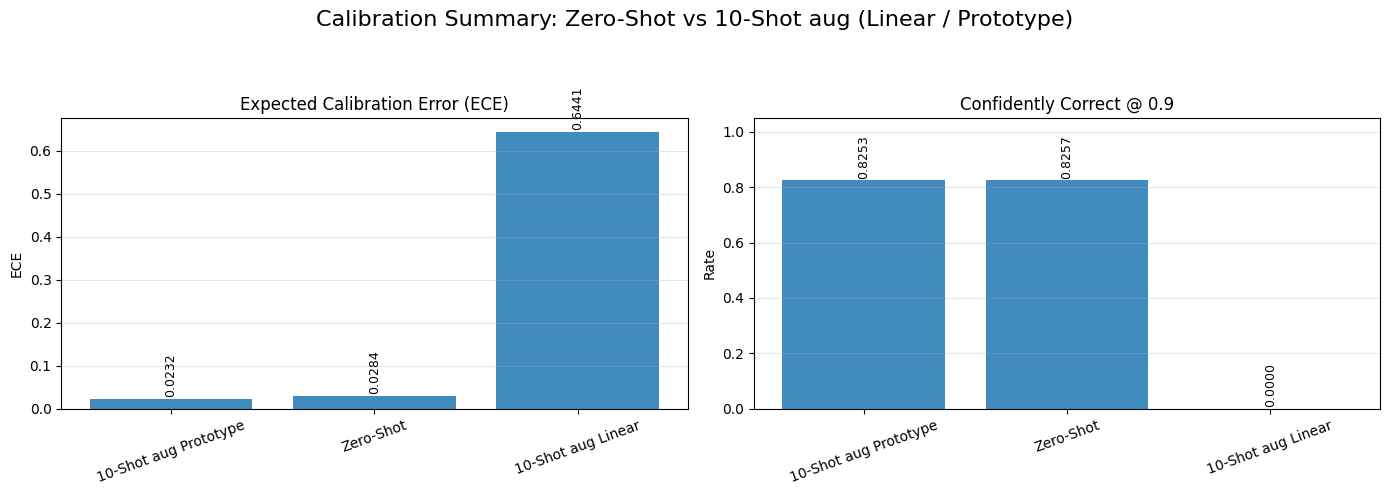
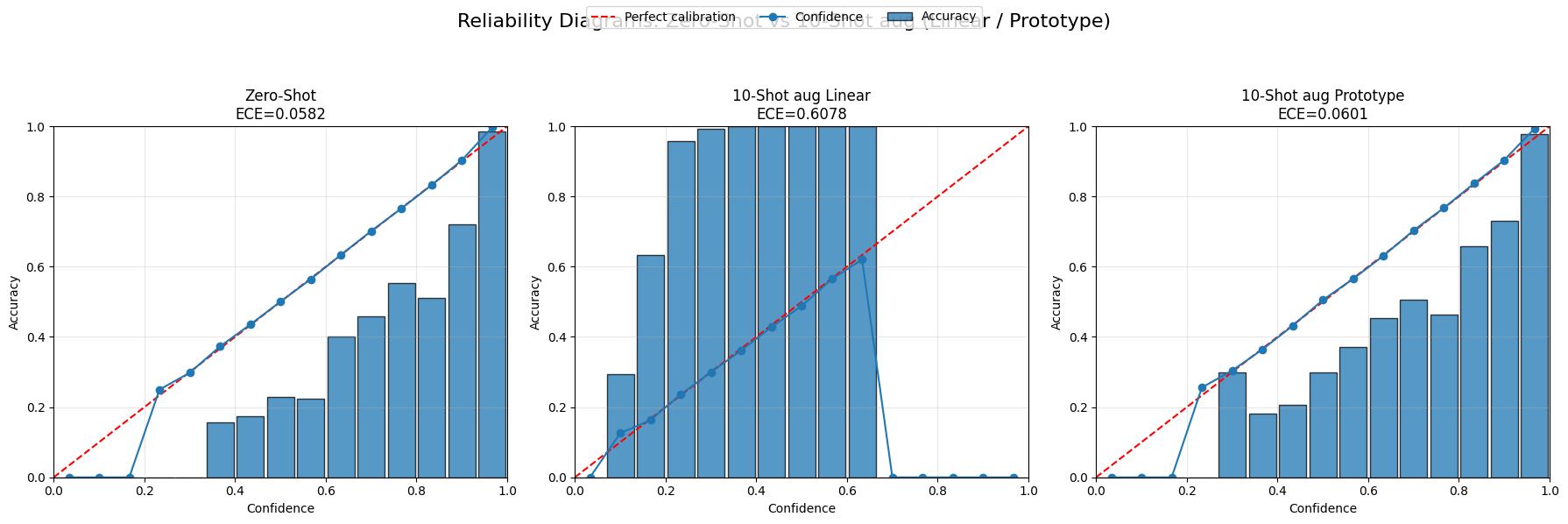
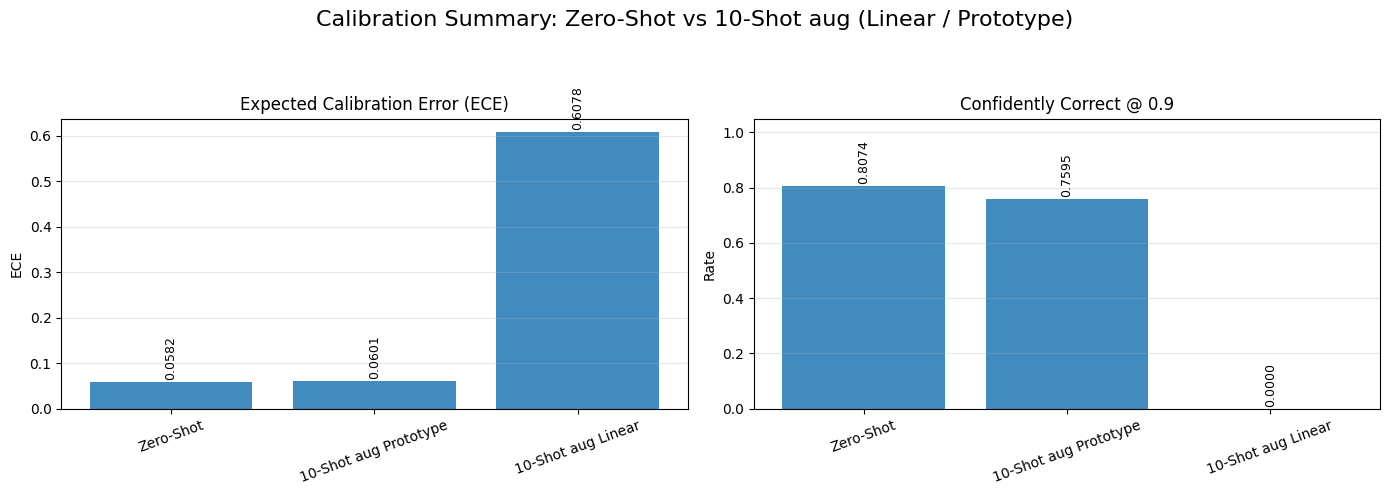
For ViT-B/16, both Zero-shot and 10-shot aug Prototype are well calibrated, with low ECE values (around 0.0284 and 0.0232). In contrast, the 10-shot aug Linear model has a very large calibration error (ECE ≈ 0.6441), meaning that it often predicts the correct class but assigns poorly calibrated confidence scores.
The same pattern appears for RN50: Zero-shot and Prototype remain reasonably calibrated, while the Linear model has a much larger ECE. The Confidently Correct scores also show that the linear models rarely produce highly confident predictions even when they are correct.
Error analysis from confusion matrices
Hard classes are visually similar fast-food categories
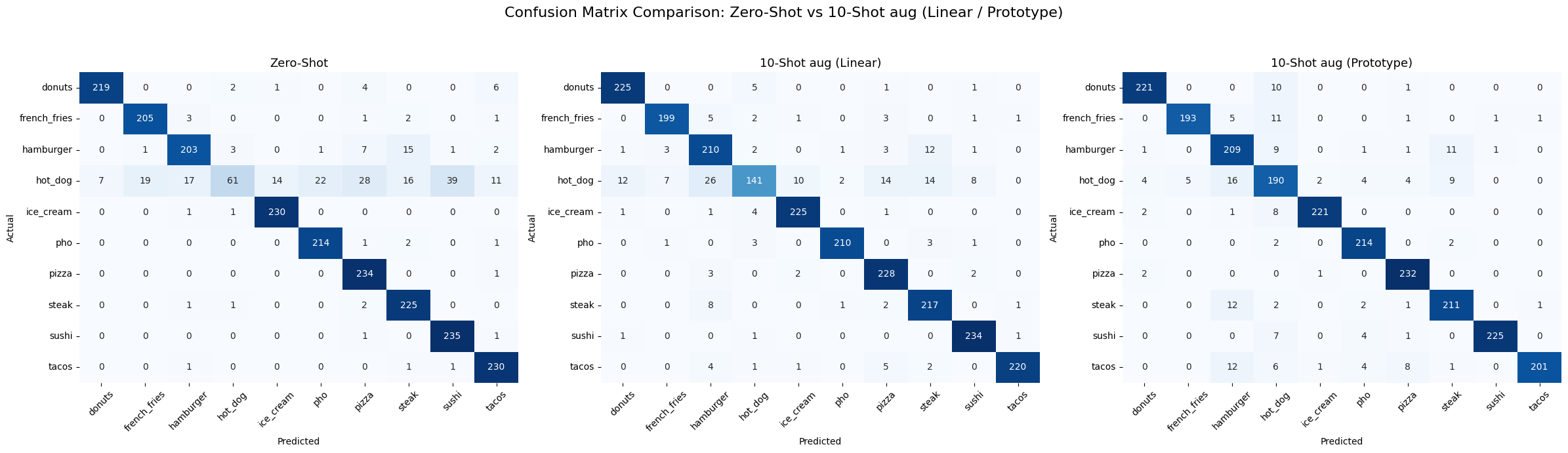
For ViT-B/16, the main source of error is the hot_dog class, which is often confused with visually similar categories such as hamburger, pizza, and steak. The 10-shot aug Prototype model reduces these confusions more effectively than the linear head.
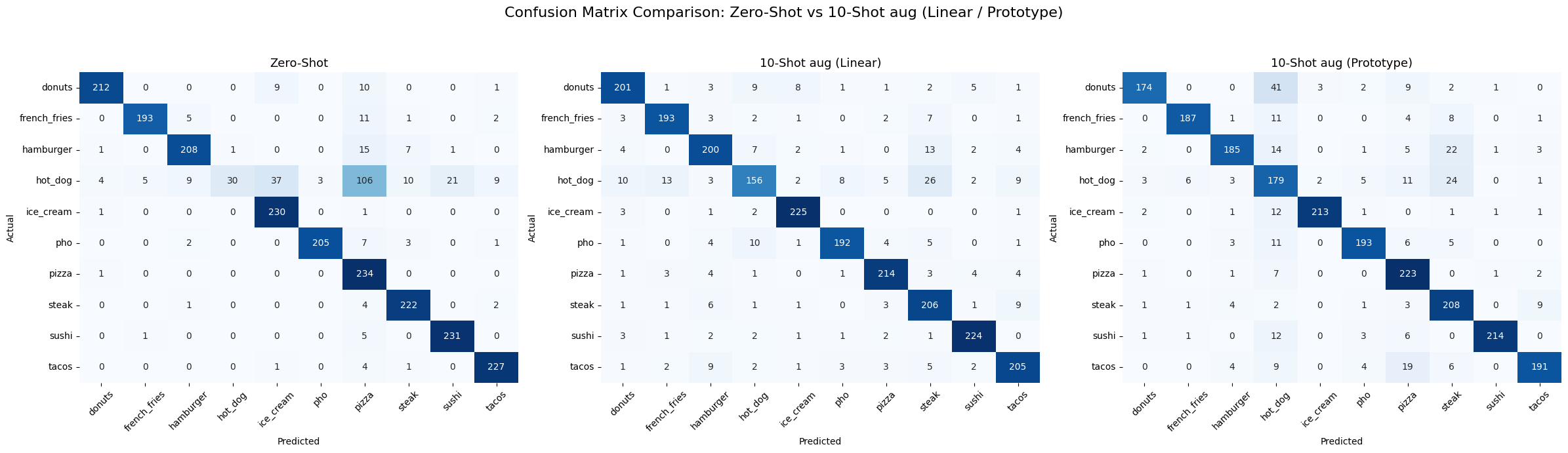
For RN50, few-shot adaptation improves several classes over zero-shot, but visually similar food items remain a major source of confusion. This is especially visible when augmentation is applied under low-shot conditions.
- Classes such as ice_cream, pizza, and sushi are consistently easier, with strong diagonal values across most settings.
- Overall, the error analysis supports the main result: Prototype-based few-shot adaptation is more robust than the Linear head, especially when class similarity is high and labeled data is limited.
Main takeaway
What the evaluation tells us
- ViT-B/16 is the stronger and more stable backbone overall.
- Prototype heads provide the best balance between accuracy, robustness, and calibration.
- Linear heads can reach competitive accuracy, but their confidence estimates are unreliable and should be interpreted carefully.
- The main remaining challenge is distinguishing fine-grained, visually similar food categories, especially under low-shot conditions.